
Colombo Gardey Julieta and Kugler María Paula, ORKB Argentinien
Einleitung
„In einer Welt, die überschwemmt wird mit bedeutungslosen Informationen, ist Klarheit Macht.“
Yuval Noah Harari, 2018
Zusammen mit der Informationsgesellschaft hat der digitale Wandel zu einer exponentiellen Zunahme der Datenerfassung und -speicherung geführt, wodurch die sogenannte Data Science entstanden ist, um der Nachfrage nach neuen Hilfsmitteln, die in der Lage sind, große Datenmengen intelligent zu verarbeiten und sie in für die Entscheidungsfindung in mannigfaltigen Umfeldern brauchbare Informationen zu überführen, nachzukommen.
Dieses Szenario lässt vermuten, dass das alte Adagio von Hobbes (1651) „Wissen ist Macht“ bald durch das neuere „Klarheit ist Macht“ (Noah Harari, 2018) ersetzt werden wird, um die Folgen eines neuen Leitbilds, das die Verwaltung von Daten, Informationen und Wissen beinhaltet, zutreffender zu vermitteln.
Dies ist eine einzigartige Gelegenheit für Oberste Rechnungskontrollbehörden (ORKB), das von neuen Technologien und der umfangreichen Datenerfassung in öffentlichen Einrichtungen gebotene Potenzial zu nutzen und es in ihre Prüfungsverfahren einzubinden, um eine bessere Verwaltung öffentlicher Gelder sicherzustellen. Data Science fungiert als Katalysator für den Prüfungswandel, der nicht nur die ORKB-Unabhängigkeit stärkt, sondern auch das Vertrauen der Öffentlichkeit sowie die Rechenschaftspflicht erhöht.
Data-Science-Methoden können Prüfungsverfahren optimieren und somit zu Prüfberichten mit mehr Wert, höherer Treffsicherheit und größerem Geltungsbereich sowie mit zeitgerechteren und relevanteren Empfehlungen führen. Qualitativ hochwertige Berichte fördern eine wirksamere und effizientere öffentliche Verwaltung, wodurch sie wesentlich zur Steigerung der Lebensqualität von Bürgerinnen und Bürgern beitragen. Um Data Science in die Prüfungsverfahren einbinden zu können, braucht es einen Aktionsplan, der ORKB bei der Verwendung dieser neuen Hilfsmittel anleiten kann.
Data Science im Prüfungsverfahren
Die Instrumente und Methoden der Data Science können in jeden Vorgang des Prüfungsverfahrens einbezogen werden. Die unten dargelegte Analyse basiert auf den INTOSAI-Leitfäden für Wirtschaftlichkeitsprüfungen und dem Modell des branchenübergreifenden Standardverfahrens für Datengewinnung (Cross-Industry Standard Process for Data Mining; CRISP-DM). Beide Verfahren greifen ständig und wiederholend ineinander. Ihre Stufen sind vergleichbar und können anlässlich der Einführung der Data Science in die Prüftätigkeit kombiniert werden.
ABBILDUNG 1
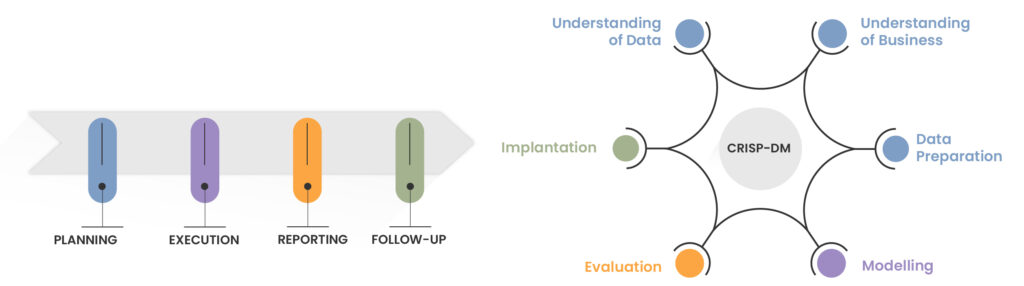
Das CRISP-DM-Modell umfasst die drei Kerndimensionen der Data Science: 1) Datenbankmanagement, 2) Entwicklung von Maschinenlernmodellen mithilfe von Algorithmen, die es Computern ermöglichen, eine Aufgabe zu erlernen, zum Beispiel die automatische Erkennung komplexer Muster, und ihre Leistung im Laufe der Zeit durch die Verwendung von Daten zu verbessern, und 3) Datenanalyse, um Daten zu untersuchen, zu bereinigen und zu verarbeiten und daraus nützliche Informationen für eine intelligente Entscheidungsfindung zu extrahieren und zu präsentieren.
ABBILDUNG 2

- Datenbankmanagement
In der Planungsphase sind sowohl die Auswahl des Prüfungsthemas als auch das Prüfungskonzept von entscheidender Bedeutung, da sie den Prüfungsgegenstand bestimmen.
In dieser Hinsicht ist die Data Science ein zentrales Hilfsmittel, mit dem sichergestellt wird, dass die in die Berichtsplanung aufzunehmenden Themen strategisch und effizient ausgewählt werden. Durch die Anwendung statistischer Modelle auf große Datenvolumen ermöglicht sie ebenfalls eine gründliche Erstbewertung des Spektrums an möglichen Prüfungsgegenständen. Dadurch können ORKB kritische Bereiche und Risiken der Prüfung präziser ermitteln und die relevantesten prüffähigen Gegenstände in Übereinstimmung mit dem Prüfungsauftrag der ORKB auswählen.
Die Erarbeitung eines Prüfplans beginnt mit einer gründlichen Suche nach relevanten Informationen. Das macht den Zugang zu Daten unerlässlich. Heutzutage ist es möglich, über zahlreiche öffentliche und private Plattformen (Scraping/Crawling, APIs, GPT) auf Open Data zuzugreifen. Diese Hilfsmittel erleichtern und beschleunigen den Zugriff auf die für Prüfungen benötigten Informationen.
Die Planung beginnt mit einer Erstbeurteilung der Struktur sowie der Zusammensetzung der Datenbank. Diese Beurteilung gibt dann Aufschluss darüber, wie sie bereinigt und verarbeitet wird, um sie an die Ziele des Prüfungsprojektes anzupassen. Dazu gehört die Abschätzung der Anzahl an Einträgen, der Arten von Variablen, der zusammenfassenden Messgrößen und des Vorhandenseins von Ausreißern, Rauschen (fehlerhaften Zeichen) und doppelten sowie etwaiger fehlender Datensätze. Die visuelle Darstellung dieser Erstbeurteilung ermöglicht eine bessere Interpretation der Rohdaten. Visualisierungstools sind ein hervorragendes Mittel für die rasche Erstellung von Zusammenfassungen, Grafiken und Berichten mit einer breiten Palette an Gestaltungsmöglichkeiten.
Die Datenqualität beeinflusst die Ergebnisse der Modelle, deren Analyse und die daraus gezogenen Schlüsse. Obwohl Organisationen bei der Digitalisierung, Standardisierung und Strukturierung von Daten Fortschritte erzielt haben, bekommen Dienststellen in der Regel Datenbanken, die vor der Verwendung bereinigt werden müssen. Daher werden in dieser Phase Rohdaten mithilfe verschiedener Techniken bereinigt und verfeinert, um einen angemessenen Datensatz zu erhalten, der die Aufgabe gemäß den Prüfungszielen erfüllen kann. Datenstruktur und -merkmale sind essenzielle Aspekte, wenn es um die Festlegung der passenden statistischen Modelle geht.
Bei Stichproben wird aufgrund des großen Potenzials der Data-Science-Tools in der Regel das gesamte Datenspektrum berücksichtigt. Eine oder mehrere Stichproben werden entnommen, um den Algorithmus zu entwickeln und zu trainieren. Auf diese Art und Weise wird ein Datensatz für die Entwicklung und das Training des Algorithmus verwendet, während andere für die Beurteilung der Prognosefähigkeit des Modells herangezogen werden.
Für jedes Data-Science-Verfahren gibt es eine schier endlose Auswahl an Softwares. Es wird empfohlen, Tools zu verwenden, die eine Interaktion mit dem Computerdenken ermöglichen und die Nutzerinnen bzw. Nutzer nicht einschränken. Zu den umfassendsten und am weitesten verbreiteten Softwares, die bei der Datenverarbeitung und -analyse zur Anwendung kommen, zählen Python und R. Bei beiden handelt es sich um höhere Programmiersprachen, die quelloffen und gratis sind. Sie bieten Instrumentarien, auch bekannt als Bibliotheken, und Funktionen, die in jeder Data-Science-Phase angewendet werden: von einfachen Visualisierungen bis hin zur Entwicklung von komplexeren Algorithmen. Einer der Hauptvorteile dieser höheren Softwareoptionen besteht darin, dass man seine eigene Funktion mit all ihren Aktionspunkten und Regeln, die auf eine Datenbank anzuwenden sind, erstellen kann und dann dieselbe Funktion mit anderen Datensätzen verwenden kann, ohne dass man Verfahren manuell duplizieren oder Codes neu schreiben muss.
ABBILDUNG 3

- Entwicklung von Maschinenlernmodellen
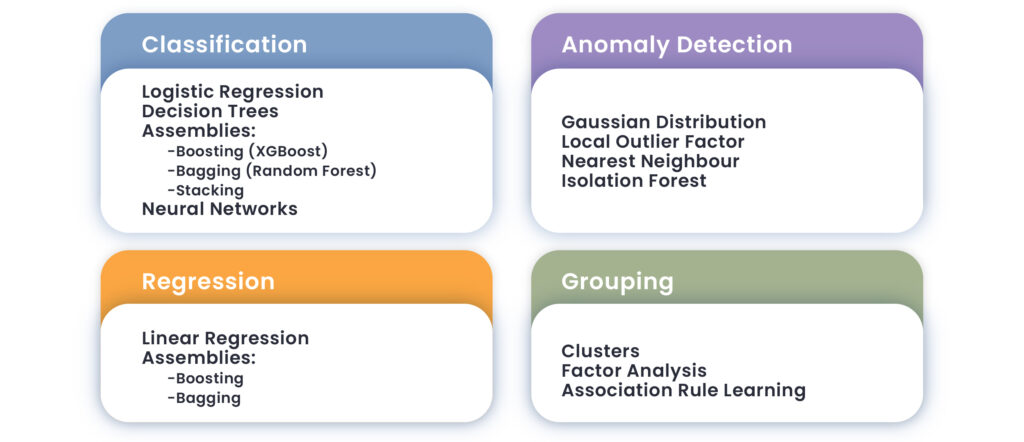
In der Ausführungs- und Modellierungsphase werden Modelle erstellt und beurteilt, um Nachweise zur Untermauerung künftiger Erkenntnisse zu sammeln. Die ausgewählten Modelle hängen vom Prüfungsziel, dem Umfang der verfügbaren Daten und der Art der Fragestellung, die beantwortet werden soll, ab. Diese können, je nachdem, wie stark ihre Variablen voneinander abhängen und welche Besonderheiten die behandelte Fragestellung aufweist, in zwei verschiedene Kategorien unterteilt werden: Modelle für überwachtes Lernen, die zum Einsatz kommen, um neue Fälle vorauszusagen (Regression), oder Modelle des unüberwachten Lernens (für die Einordnung und Bündelung von Fällen). Die folgende Grafik enthält Beispiele für diese Lernmodelle in Bezug auf die Art der auszuführenden Aufgabe:
ABBILDUNG 4
Jedes Modell sollte anhand der Validierungsdaten beurteilt werden, um dessen Vorhersage- oder Einordnungsfähigkeit zu bestimmen. Dafür gibt es verschiedene Techniken zur Messung von Varianz, Verzerrung, Fehlern und den Kosten für das Aufspüren dieser Fehler. Anschließend wird das Modell auf die restlichen Daten angewendet, um sachdienliche und treffsichere Nachweise zur Untermauerung von Empfehlungen zu finden.
ABBILDUNG 5

- Datenanalyse
In der Berichterstattungsphase spielen Visualisierungstools eine extrem bedeutende Rolle. Die von der Data Science gebotene Vielfalt und Anzahl an Visualisierungsmöglichkeiten stellen eine bedeutende Verbesserung dar, weil sie Informationen mittels qualitativ hochwertigen Grafiken und Videos deutlich vermitteln. Dabei bieten sie auch die Möglichkeit, verschiedene ästhetische Parameter auszuwählen und Berichte einfach zu erstellen. Darüber hinaus gibt es mehrere intuitive Tools (Power BI und Tableau), welche die Erstellung von als Entscheidungsgrundlagen dienenden Dashboards ermöglichen (auch bekannt als Geschäftsanalytik).
ABBILDUNG 6

Data-Science-Techniken ermöglichen die Automatisierung von Prüfungsverfahren. Durch die unveränderte Beibehaltung von Kriterien und die Hinzufügung oder den Austausch von Daten (Input) ist das Modell in der Lage, Kontinuität bzw. Brüche (Anomalien) in den analysierten Informationen ausfindig zu machen.
ABBILDUNG 7

ABBILDUNG 8
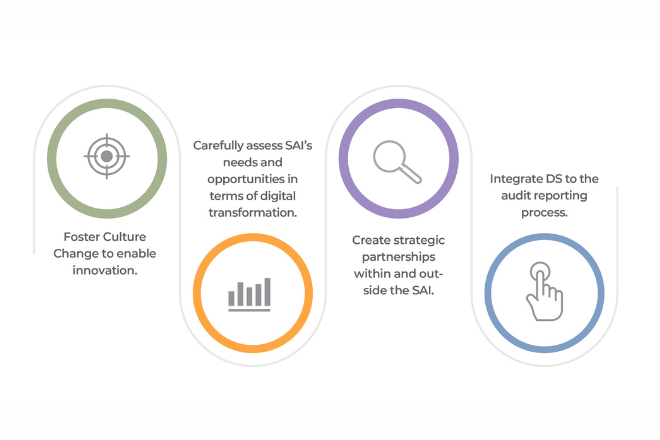
Strategische Aktionspunkte
ABBILDUNG 9
Fazit
Der strategische und progressive Einsatz von Informationstechnologien in den Prüfungstätigkeiten birgt das Potenzial, bedeutende Veränderungen in den Prüfungsverfahren voranzutreiben.
Die Vorteile der Einbindung von Data Science machen die Risiken bei weitem wett. Daher wird dringend empfohlen, dass ORKB damit beginnen, ihre Prüfungs- und Überwachungstätigkeiten neu zu konzipieren, um diese Praktiken einzubeziehen.
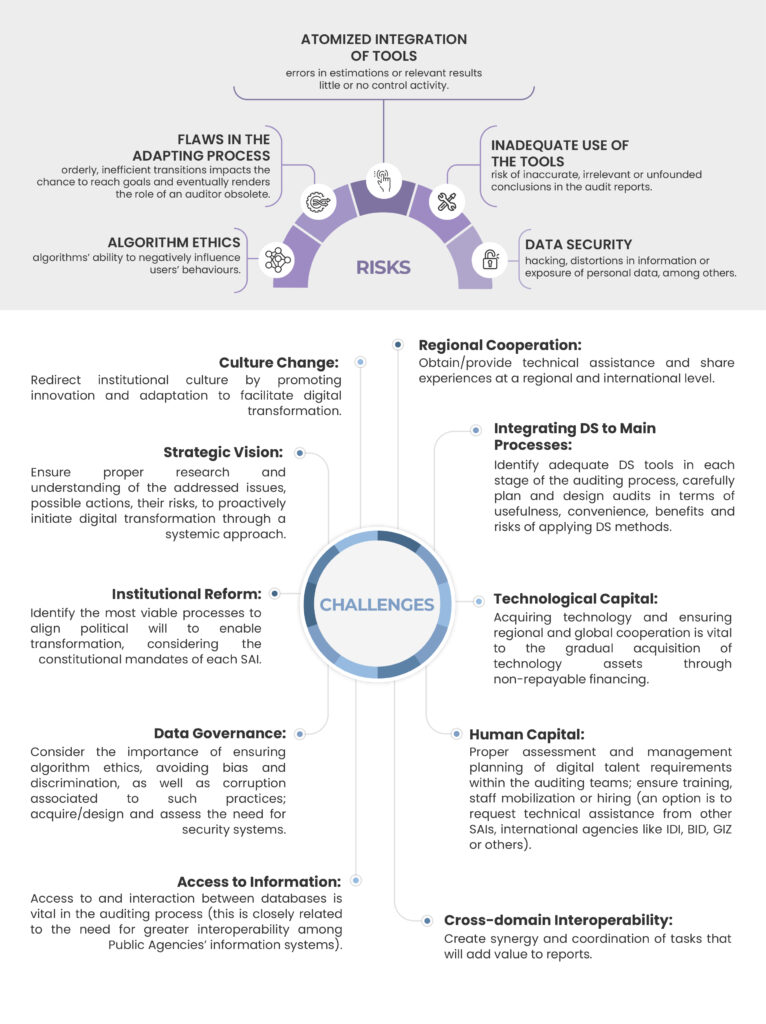
Es wurde eine Reihe strategischer Leitlinien umrissen, um sicherzustellen, dass die Einbindung von Data Science in Prüfungsverfahren nicht als isolierte Maßnahme, sondern vielmehr als Teil von mehreren Schritten in Richtung einer graduellen Steigerung angesehen wird.
Besonders hervorgehoben wurde die einzigartige Gelegenheit für ORKB, ihre Rolle zu stärken und ihre bereichsübergreifenden sowie multidisziplinären Tätigkeiten zu nutzen, um die kulturellen Veränderungen, die der digitale Wandel erfordert, anzuführen. Dabei handelt es sich um eine enorme Herausforderung, deren Bewältigung allerdings nicht nur notwendig und zeitgemäß, sondern auch praktikabel und machbar ist. Anstatt Technologie als Einschränkung oder als Selbstzweck anzusehen, ist es wichtig, die positiven Auswirkungen von Data Science zu verstehen, um zu vermeiden, „das Pferd vom Schwanz her aufzuzäumen“ bzw. Technologie vor Wissen zu stellen.
Dem digitalen Wandel sollte mit konkreten Maßnahmen und einem starken politischen Willen, der auf die Bekämpfung von Korruption ausgerichtet ist, begegnet werden. Deswegen sollte das Thema Data Governance umfassend und effektiv in Angriff genommen werden.
Eine zeitnahe, präzise und effiziente staatliche Kontrolle gestützt auf Data Science schafft Mehrwert für die Verwaltung und optimiert dabei die Staatsausgaben. Darüber hinaus kann die Ausschöpfung des technologischen Potenzials zur Einführung von Data Science einen Beitrag zur Reduktion des Entwicklungsgefälles leisten und die Grundlage für ein robusteres und nachhaltigeres weltweites Wachstum legen.


