
La science des données comme catalyseur de la transformation de l’audit
Colombo Gardey Julieta et Kugler María Paula, Cour des comptes de l’Argentine
Introduction
« Dans un monde noyé sous les informations inutiles, le pouvoir, c’est la clarté »
Yuval Noah Harari, 2018
Dans le contexte de la société de l’information, la transformation numérique a entraîné une croissance exponentielle de la production et du stockage des données, donnant naissance à ce que l’on appelle la science des données, pour répondre au besoin de nouveaux outils capables de traiter intelligemment de grands volumes de données et de les transformer en informations exploitables pour la prise de décision dans de multiples environnements.
Ce scénario suggère que le vieil adagio de Hobbes (1651), « L’information, c’est le pouvoir », sera bientôt remplacé par le plus récent « Le pouvoir, c’est la clarté » (Noah Harari, 2018) pour transmettre plus précisément les implications d’un nouveau modèle impliquant la gestion des données, de l’information et de la connaissance.
Il s’agit d’une occasion unique pour les Institutions supérieures de contrôle des finances publiques (ISC) d’exploiter le potentiel offert par les nouvelles technologies et la grande quantité de données générées au sein des organismes publics, et de les intégrer dans leurs processus d’audit afin de garantir une meilleure gestion des fonds publics. La science des données fonctionne comme un catalyseur de la transformation de l’audit, qui renforce l’indépendance des ISC tout en augmentant la confiance du public et la responsabilité.
Les méthodologies de la science des données peuvent optimiser les processus d’audit, conduisant à des rapports d’audit de plus grande valeur, précision et portée, ainsi qu’à des recommandations plus opportunes et plus pertinentes. Des rapports de qualité favorisent une administration publique plus efficace et efficiente, ce qui a un impact significatif sur l’amélioration de la qualité de vie des citoyens. L’intégration de la science des données dans les processus d’audit nécessite une feuille de route qui puisse guider les ISC dans l’utilisation de ces nouveaux outils.
La science des données dans le processus d’audit
La science des données, les outils et les techniques peuvent être intégrés à n’importe quel stade du processus d’audit. L’analyse ci-dessous est basée sur les lignes directrices de l’INTOSAI pour les audits de performance et sur le modèle CRISP-DM (Cross-Industry Standard Process for Data Mining). Les deux processus se fondent constamment l’un dans l’autre de manière itérative. Leurs étapes sont comparables et peuvent être combinées au fur et à mesure que la science des données est introduite dans l’activité d’audit :
FIGURE 1
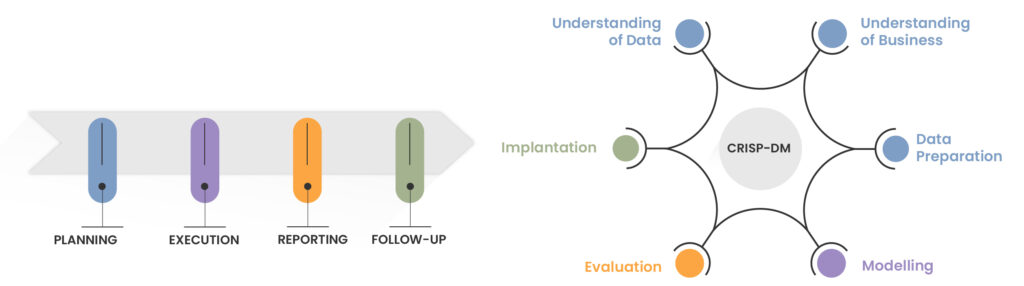
Le modèle CRISP-DM comprend les trois dimensions fondamentales de la science des données : 1) la gestion des bases de données ; 2) la création de modèles d’apprentissage automatique par le biais d’algorithmes qui permettent aux ordinateurs d’apprendre une tâche, comme la reconnaissance automatique de modèles complexes et l’amélioration de leurs performances au fil du temps grâce à l’utilisation de données ; et 3) l’analyse des données, pour explorer, nettoyer et transformer les données afin d’extraire et de présenter des informations utiles pour une prise de décision intelligente.
FIGURE 2

- Gestion de base de données
Lors de la phase de préparation, la sélection du sujet et la conception de l’audit sont essentielles, car elles déterminent ce que sera l’objet de l’audit.
En ce sens, la science des données est un outil clé qui garantit que les sujets à inclure dans la planification du rapport sont sélectionnés de manière stratégique et efficace. Elle permet également une évaluation initiale approfondie de l’univers des objets d’audit possibles grâce à des modèles statistiques appliqués à de grands volumes de données. Cela permet aux ISC d’identifier plus précisément les points critiques et les risques, et de sélectionner les objets à auditer les plus pertinents, conformément au mandat de l’ISC.
La conception d’un plan d’audit commence par une recherche approfondie des informations pertinentes, ce qui rend l’accès aux données essentiel. Aujourd’hui, il est possible d’accéder à des données ouvertes sur de multiples plateformes publiques et privées (scraping/crawling, API, GPT). Ces outils facilitent et accélèrent l’accès aux informations nécessaires aux audits.
La planification commence par une évaluation initiale de la structure et de la composition de la base de données, et cette évaluation informe sur la manière dont elle sera nettoyée et transformée pour l’adapter aux objectifs du projet d’audit. Il s’agit d’estimer le nombre de registres, les types de variables, les mesures sommaires et la présence de valeurs aberrantes, de bruit (caractères d’erreur) et de données dupliquées, ainsi que de toute donnée manquante. La présentation visuelle de cette évaluation exploratoire permet une meilleure interprétation des données brutes. Les outils de visualisation sont une excellente ressource pour créer des résumés, des graphiques et des rapports rapidement et avec une grande variété de conceptions.
La qualité des données a un impact sur les résultats des modèles, leur analyse et les conclusions tirées. Bien que les organisations aient progressé dans la numérisation, la normalisation et la structuration des données, les agences obtiennent généralement des bases de données qui doivent être nettoyées avant d’être utilisées. Au cours de cette étape, les données brutes sont donc nettoyées et affinées à l’aide de diverses techniques, afin d’obtenir un ensemble de données adéquat pour effectuer le travail en fonction des objectifs de l’audit. La structure et les caractéristiques des données sont des aspects essentiels lorsqu’il s’agit de définir les modèles statistiques pertinents.
En ce qui concerne l’échantillonnage, en règle générale, l’ensemble de l’univers des données est pris en compte, en raison du grand potentiel des outils de la science des données. Un ou plusieurs échantillons sont obtenus pour créer et entraîner les algorithmes. De cette manière, un ensemble de données est utilisé pour créer et entraîner l’algorithme, et d’autres sont utilisés pour évaluer la capacité de prévision du modèle.
Les options logicielles disponibles pour chaque processus de la science des données sont pratiquement infinies. Il est recommandé d’utiliser des outils qui permettent d’interagir avec la pensée informatique et qui ne limitent pas l’utilisateur. Les logiciels les plus complets et les plus largement utilisés pour le traitement et l’analyse des données sont Python et R. Ces deux logiciels sont libres, gratuits et leur langage est de haut niveau. Ils offrent des boîtes à outils connues sous le nom de bibliothèques et de fonctions utilisées à chaque étape de la science des données, de la simple visualisation à la construction d’algorithmes plus complexes. L’un des principaux avantages de ces logiciels de haut niveau est qu’il est possible de créer sa propre fonction avec toutes ses actions et règles à appliquer à une base de données, puis d’utiliser cette même fonction avec d’autres ensembles de données sans avoir à dupliquer les processus manuellement ou à réécrire des codes.
FIGURE 3

- Création de modèles d’apprentissage automatique
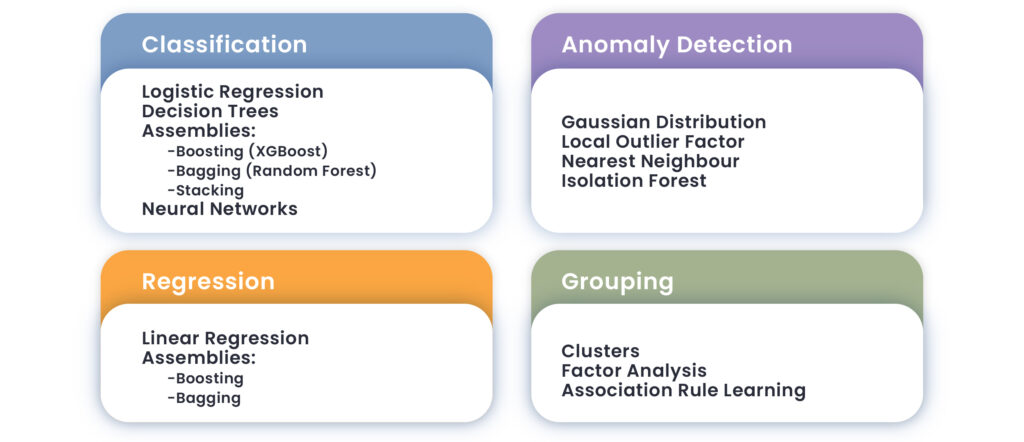
Au cours de la phase d’exécution et de modélisation, des modèles sont créés et évalués afin de trouver des éléments probants qui étayeront les constatations futures. Les modèles choisis dépendent de l’objectif de l’audit, de l’ampleur des données disponibles et du type de question à traiter. Ils peuvent être classés en deux catégories distinctes, en fonction du degré de dépendance des variables entre elles et des particularités de la question traitée : les modèles d’apprentissage supervisés, utilisés pour prédire de nouveaux cas (régression) ou les modèles d’apprentissage non supervisés (utilisés pour trier et regrouper les cas). Le tableau suivant contient des exemples de ces nœuds d’apprentissage en fonction du type de tâche à accomplir :
FIGURE 4
Chaque modèle doit être évalué par rapport aux données de validation afin de déterminer sa capacité de prédiction ou de classification. À cette fin, il existe différentes techniques pour mesurer les écarts, les biais, les erreurs et le coût de la détection de ces erreurs. Le modèle est ensuite appliqué aux données restantes afin de trouver des preuves pertinentes et précises pouvant étayer les recommandations.
FIGURE 5

- Analyses de données
Au stade de l’établissement des rapports, les outils de visualisation jouent un rôle extrêmement important. La variété et le nombre d’options de visualisation offertes par la science des données représentent une amélioration significative puisqu’elles transmettent clairement les informations par le biais de graphiques et de vidéos de haute qualité, avec la possibilité de sélectionner différents paramètres esthétiques et de créer facilement des rapports. En outre, il existe plusieurs outils intuitifs (Power BI et Tableau) qui permettent de créer des tableaux de bord pour éclairer la prise de décision (ce que l’on appelle l’intelligence économique).
FIGURE 6

Les techniques de science des données permettent d’automatiser les processus d’audit. En conservant les critères inchangés et en ajoutant ou en remplaçant des données (entrées), le modèle peut permettre de détecter des continuités et/ou des ruptures (anomalies) dans les informations analysées.
FIGURE 7

FIGURE 8
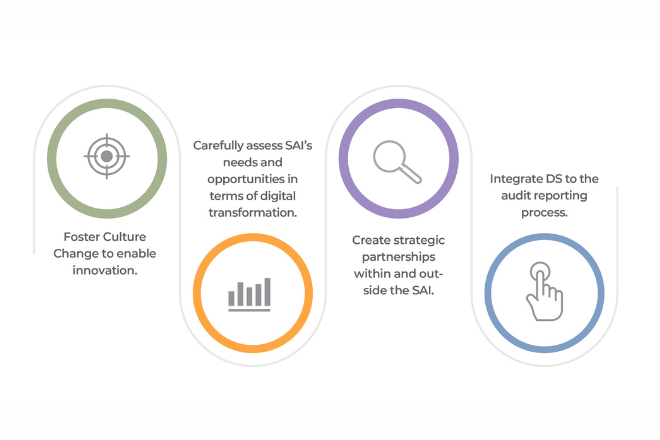
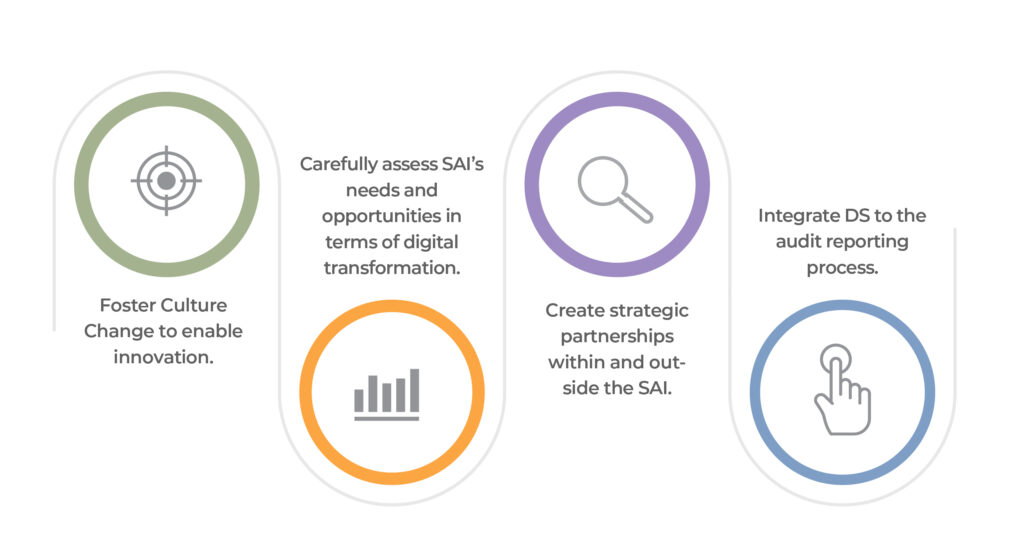
Actions stratégiques
FIGURE 9
Conclusion
Le déploiement stratégique et progressif des technologies de l’information pour les activités d’audit peut entraîner des changements significatifs dans les processus d’audit.
Les avantages de l’intégration de la science des données l’emportent de loin sur les risques. C’est pourquoi il est fortement conseillé aux ISC de commencer à repenser leurs activités de contrôle et de suivi pour y inclure cette pratique.
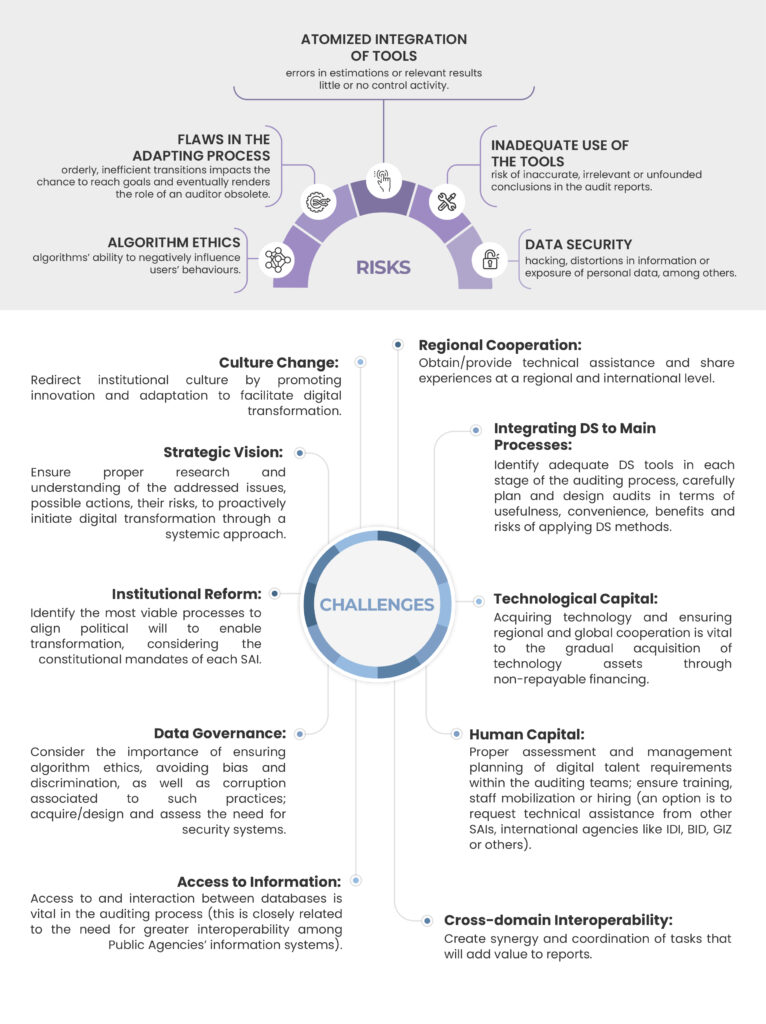
Une série de lignes directrices stratégiques ont été définies pour faire comprendre que l’intégration de la science des données dans les processus d’audit ne doit pas être considérée comme une mesure isolée, mais plutôt comme faisant partie d’un ensemble d’étapes vers une escalade graduelle.
Un accent particulier a été mis sur l’opportunité unique qu’ont les ISC de renforcer leur rôle et de capitaliser leurs activités transversales et multidisciplinaires pour être le fer de lance du changement de culture qu’exige la transformation numérique. Il s’agit d’un défi énorme, le relever n’est pas seulement nécessaire et opportun, mais aussi viable et faisable. Plutôt que de considérer la technologie comme une limite ou une fin en soi, il est important de comprendre l’impact positif de la science des données, afin d’éviter de « mettre la charrue avant les bœufs », ou la technologie avant la connaissance.
La transformation numérique doit être abordée par le biais de mesures spécifiques et d’une forte volonté politique orientée vers la lutte contre la corruption. À cette fin, la gouvernance des données devrait être largement et efficacement prise en compte.
Un contrôle gouvernemental opportun, précis et efficace basé sur la science des données ajoute de la valeur à l’administration, en optimisant les dépenses publiques. En outre, tirer parti du potentiel de la technologie pour mettre en œuvre la science des données peut contribuer à réduire les écarts de développement et jeter les bases d’une croissance plus solide et durable à l’échelle mondiale.


