
par Tiare Rivera, Institution supérieure de contrôle des finances publiques du Chili (CGR)
Introduction
Les Institutions supérieures de contrôle des finances publiques (ISC) sont la pierre angulaire du maintien de la responsabilité, de la transparence et de l’efficacité dans le secteur public, en particulier dans les opérations gouvernementales.
Cependant, la technologie évoluant à une vitesse fulgurante, il est impératif que les ISC adoptent des technologies de données de pointe, telles que l’apprentissage automatique (ML), pour révolutionner leurs processus d’audit. Grâce à ML, les ISC peuvent améliorer l’efficience, la précision et l’efficacité, en fournissant une analyse plus complète et axée sur les données des opérations gouvernementales, garantissant ainsi les normes les plus élevées en matière de responsabilité et de confiance.
Engager les ISC dans les technologues de données avancées
Plusieurs étapes doivent être franchies pour guider une Institution supérieure de contrôle des finances publiques vers l’intégration et l’utilisation efficace des technologies de données avancées telles que l’apprentissage automatique :
Élaborer une stratégie claire : une ISC axée sur les données et les technologies doit disposer d’une stratégie claire décrivant les buts et les objectifs de l’organisation. Cette stratégie doit être élaborée avec la participation de toutes les parties prenantes, y compris les auditeurs, les professionnels de l’informatique et les experts en la matière.
Investir dans la technologie : les ISC doivent investir dans la technologie et les outils nécessaires à la collecte, au stockage et à l’analyse de grandes quantités de données. Il s’agit notamment d’investir dans des systèmes de gestion des données, des outils d’analyse des données et des technologies d’IA/ML.
Constituer une main-d’œuvre qualifiée : pour utiliser efficacement les données et la technologie dans le processus d’audit, les ISC ont besoin d’une main-d’œuvre qualifiée, formée à l’analyse des données, à la technologie et aux méthodologies d’audit. Il s’agit notamment de former les auditeurs aux techniques d’analyse des données et d’embaucher des professionnels de l’informatique et des scientifiques des données pour soutenir le processus d’audit.
Promouvoir la prise de décision fondée sur les données : les ISC doivent promouvoir la prise de décision fondée sur les données dans l’ensemble de l’organisation. Il s’agit notamment d’utiliser les données pour bien vouloir informer la planification de l’audit et l’évaluation des risques, et d’intégrer l’analyse des données dans le processus d’audit.
Élaborer des partenariats : les ISC doivent élaborer des partenariats avec d’autres organisations, telles que les agences gouvernementales, afin d’accéder aux données et de les partager, et de collaborer au développement et à l’utilisation de la technologie dans le processus d’audit.
Investir dans les données : les données collectées et stockées par les ISC doivent être nettoyées, mises à l’échelle et transformées pour produire des résultats une fois l’analyse avancée effectuée.
Créer les algorithmes : les modèles à utiliser doivent être sélectionnés en fonction du type d’informations recherchées, et le modèle doit être formé et affiné pour produire de meilleurs résultats. Le modèle doit être évalué sur des ensembles de tests en vue d’une application ultérieure à des données réelles, et les modèles finaux doivent être contrôlés et entretenus régulièrement.Contrôle et amélioration continus : les ISC doivent surveiller et évaluer en permanence l’utilisation de la technologie et des données dans le processus d’audit afin d’identifier les domaines à améliorer et de procéder aux ajustements nécessaires. Il s’agit notamment d’examiner et de mettre à jour régulièrement la stratégie de l’organisation en matière de technologie et de données.
Caractéristiques fondamentales des algorithmes d’apprentissage automatique
Une fois que l’ISC est prête à passer à l’étape suivante, il existe deux approches fondamentales pour appliquer l’apprentissage automatique, en fonction de la disponibilité de données appropriées et de l’existence d’une structure sous-jacente dans ces données.
Apprentissage supervisé : ces algorithmes sont utilisés pour classer et prédire les résultats en s’appuyant sur des données de formation étiquetées. Ils peuvent être utilisés par les ISC pour classer les transactions comme frauduleuses ou non, prédire la probabilité de fraude dans un domaine donné ou classer les fournisseurs comme présentant un risque élevé ou faible.
Apprentissage non supervisé : ces algorithmes sont utilisés pour identifier des modèles et des structures dans des données non étiquetées. Ils peuvent être utilisés par les ISC pour identifier des schémas de mauvaise gestion financière, détecter des transactions suspectes ou identifier des valeurs aberrantes dans les schémas de dépenses.
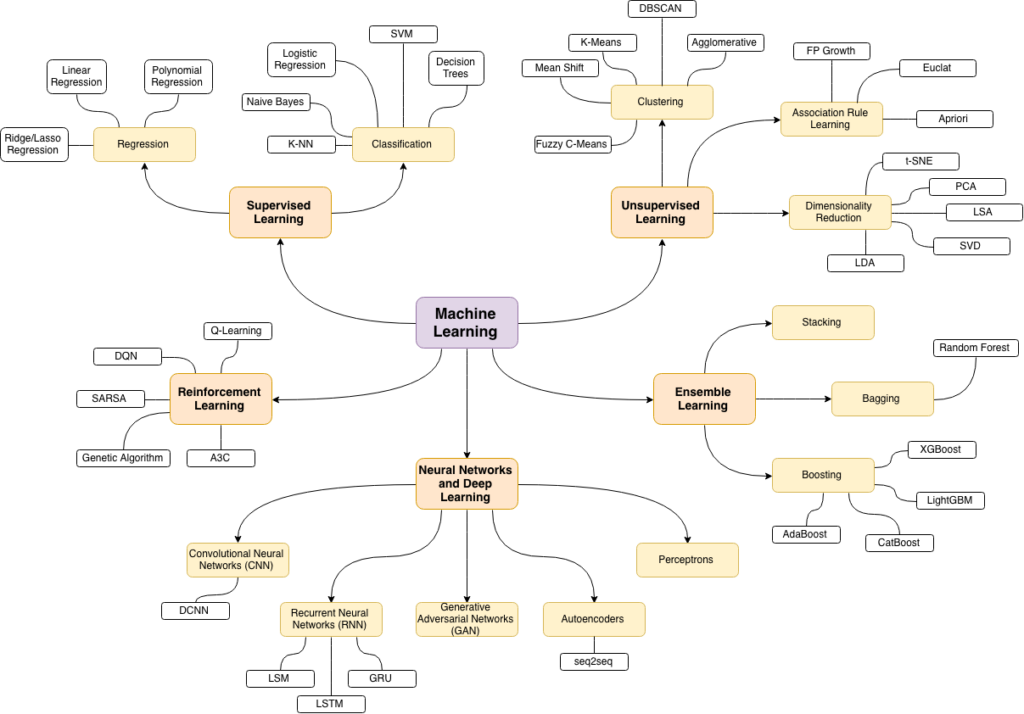
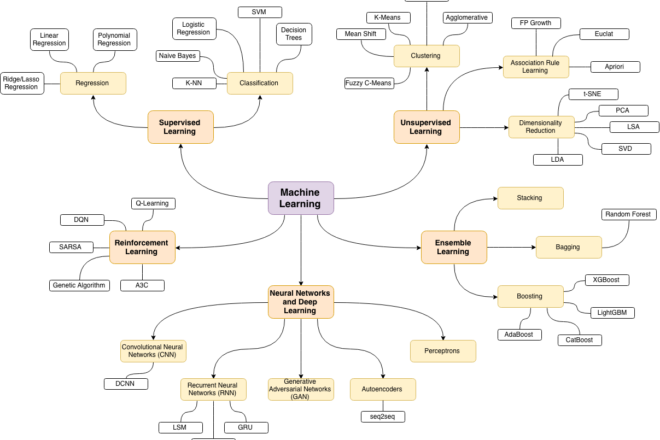
Types d’algorithmes de l’apprentissage automatique pouvant être utilisés par les ISC
Il existe plusieurs types d’algorithmes d’apprentissage automatique qui peuvent être utilisés dans les ISC pour améliorer l’efficience, la précision et l’efficacité du processus d’audit. Voir le diagramme pour une vue d’ensemble.
Voici quelques-uns des algorithmes d’apprentissage automatique les plus couramment utilisés et leurs applications potentielles dans les ISC :
Clustering (regroupement) : ces algorithmes regroupent des points de données similaires. Ils peuvent être utilisés dans les ISC pour regrouper des ensembles de données similaires, comme les dépenses par département, ou pour identifier des groupes de programmes ou de projets gouvernementaux similaires, ce qui facilite la comparaison et l’évaluation de leurs performances.
Détection des anomalies : ces algorithmes sont utilisés pour détecter les points de données qui s’écartent de manière significative de la norme. Ils peuvent être utilisés dans les ISC pour détecter les irrégularités budgétaires ou pour prioriser les audits en s’appuyant sur les domaines où la performance s’écarte des modèles attendus.
Réseaux neuronaux artificiels : ces algorithmes s’inspirent de la structure du cerveau humain et peuvent être utilisés pour une série de tâches, y compris la reconnaissance d’images et de la parole et le traitement du langage naturel. Ils peuvent être utilisés dans les ISC pour traiter et analyser de grandes quantités de données non structurées, telles que des textes et des images, et en extraire des informations.
Arborescences de décision : ces algorithmes sont utilisés pour classer des points de données en s’appuyant sur un ensemble de règles de décision. Ils peuvent être utilisés par les ISC pour classer les transactions comme frauduleuses ou non, pour classer les fournisseurs comme présentant un risque élevé ou faible, ou pour prédire la probabilité de fraude dans un domaine donné.
K-Voisins les plus proches : ces algorithmes sont utilisés dans les applications de reconnaissance d’images et de vidéos, d’analyse des stocks et de reconnaissance de l’écriture manuscrite. Il utilise des points de données étiquetés pour étiqueter d’autres points. La méthodologie consiste à créer un système de vote des plus proches voisins. Le « k » est le nombre de voisins qu’il vérifie. Ses avantages sont la simplicité de mise en œuvre et le fait qu’il fonctionne bien avec des données bruitées. Leur principal inconvénient est qu’ils nécessitent une quantité importante de calculs, ce qui peut s’avérer coûteux pour les grands ensembles de données.
Obstacles potentiels
S’il existe des outils ML pour la détection des fraudes et la surveillance financière, il n’est pas toujours facile de les mettre en œuvre de manière opérationnelle, d’adopter de nouveaux outils numériques ou de les intégrer dans les institutions d’audit. Il existe plusieurs obstacles à l’innovation en matière d’apprentissage automatique dans les ISC et les agences gouvernementales.
Par exemple, de nombreuses ISC peuvent ne pas disposer de données précises ou cohérentes, ce qui peut avoir un impact négatif sur la performance des algorithmes d’apprentissage automatique et limiter leur efficacité. Un manque d’expertise technique peut affecter la capacité des ISC à mettre en œuvre et à utiliser avec succès les algorithmes d’apprentissage automatique, ce qui nécessite une formation et un soutien spécialisés. En outre, les ISC peuvent avoir besoin d’intégrer ces algorithmes dans leurs systèmes et processus existants, ce qui peut s’avérer difficile et nécessiter des ressources importantes.
De nombreuses agences sont confrontées à des obstacles culturels et structurels au changement. Il s’agit notamment d’une réticence à innover, d’une préférence pour le statu quo, d’une peur de l’échec, d’un cloisonnement excessif où différents services traitent des données et des segments différents de missions clés, et d’un manque de dirigeants et de gestionnaires capables de faciliter le changement. Dans de nombreuses organisations, les obstacles au changement ne sont pas seulement techniques, mais aussi structurels, opérationnels, liés à la gestion et culturels. Si les dirigeants ne s’engagent pas à créer une culture de l’innovation, l’adoption de nouvelles technologies ne produira presque jamais les avantages escomptés.
Considérations déontologiques et reddition de comptes :
Les modèles d’apprentissage automatique ont le potentiel de perpétuer ou même d’exacerber les préjugés sociétaux. Il est donc important de prendre en compte les implications déontologiques du modèle, d’être conscient de ses limites et de prendre des mesures pour atténuer les conséquences négatives.
Toutes ces préoccupations sont limitées dans un environnement qui repose sur le jugement humain. Par conséquent, l’utilisation de l’apprentissage automatique dans l’audit pour lutter contre la corruption et la fraude pose des défis éthiques, juridiques et de gouvernance uniques.
L’un des plus grands défis consiste à déterminer comment traduire les grands principes éthiques tels que la justice, l’équité, la confidentialité, la transparence, la responsabilité et la sécurité humaine dans des applications concrètes. Ces principes sont parfois contradictoires et les ISC doivent définir leur signification dans le contexte d’un système particulier et déterminer comment évaluer les algorithmes d’apprentissage automatique en conséquence.
Par ailleurs, certains modèles sont complexes et difficiles à interpréter. Il est important de comprendre le processus de prise de décision du modèle et de disposer de modèles interprétables pour expliquer le raisonnement qui sous-tend la décision du modèle.
Effets escomptés de l’utilisation de l’apprentissage automatique par les ISC
L’un des principaux avantages d’intégrer des technologies de données avancées dans le processus d’audit est la capacité d’analyser rapidement et avec précision de grandes quantités de données et d’identifier des modèles et des tendances qui pourraient ne pas être évidents pour les auditeurs humains. Cela peut aider les ISC à identifier les fraudes potentielles ou la mauvaise gestion financière et à prendre des décisions plus éclairées sur les domaines dans lesquels elles doivent concentrer leurs efforts d’audit.
En automatisant certaines tâches, telles que la saisie et l’analyse des données, les auditeurs peuvent se concentrer sur des tâches plus complexes et à forte valeur ajoutée, telles que l’interprétation des résultats de l’audit et la formulation de recommandations d’amélioration.
L’utilisation de l’apprentissage automatique par les Institutions supérieures de contrôle des finances publiques a le potentiel d’améliorer la capacité des ISC à communiquer et à s’engager auprès du public en fournissant des outils interactifs tels que des tableaux de bord en temps réel et des rapports personnalisables. Ces effets attendus pourraient conduire à un secteur public plus transparent et plus responsable, contribuant ainsi à une meilleure gouvernance et à la confiance dans les institutions.


